你写的C语言代码,为什么比我的快了3倍?
吾尝终日而码矣,不如须臾之所学也
概述
本文章是在解决一个实际问题时产生的,这个问题已经简单到熟透了——求斐波那契数,也就是:
斐波那契数的求解算法有最暴力的
为了把目光放到更核心的问题上,本文章只讨论cnt,输出从cnt个斐波那契数构成的序列。本文章展示了不同写法的C语言代码被编译后的汇编代码表现,并以此讨论不同汇编代码的行为导致的常数时间差异及其原因。
实验
先贴实验结果:
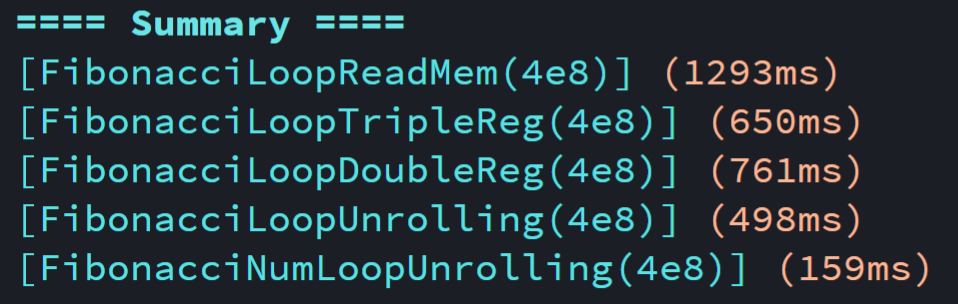
实验环境为
- CPU: Intel Core i5-1035G4 @1.10GHz
- RAM: 8.00 GB
- OS: Windows 11 x64 21H2
- 其他软件
- Windows Subsystem for Linux 5.10.102.1
- VSCode x64 1.67.1
- gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
- 编译参数:gcc -Wall -Og -S
完整实验代码在文末给出,接下来只讨论简版代码
0:简单暴力的常规写法
这个应该是绝大多数写
1 | // FibonacciLoopReadMem |
1 | # FibonacciLoopReadMem |
查看C代码和汇编代码可以发现,for循环中的一轮计算fib[i]=fib[i-1]+fib[i-2],总共访问了3次内存:
- 读取
fib[i-2]即movq -16(%rax,%rcx), %rsi - 读取
fib[i-1]并加到第一次读取的值中,即addq -8(%rax,%rcx), %rsi - 将第2步计算的结果写入
fib[i],即movq %rsi, (%rax,%rcx)
计算机中,寄存器就是CPU的亲儿子,CPU对它的访问速度要远远快过对内存的访问。更重要的是,CPU不能直接在内存上进行计算,因为内存上的数据不能直接连接到计算单元(怎么可能做到数亿条线从CPU直接连接到内存单元?),内存上的数据要参与运算时得先被读出来。(指令addq -8(%rax,%rcx), %rsi看起来像是直接用内存上的数参与加法,实际上可以看作-8(%rax,%rcx)的值被存储到一个无名寄存器中)
而我们把数据从寄存器上写到内存中,然后就不管它在寄存器上的值了;而存在内存上的数据,在下一次参与加法运算时又要读回到寄存器上,何不保留寄存器中的值,来减少这些内存读取呢?
1:使用3个寄存器的滑动来减少访存
for循环中的一轮计算fib[i]=fib[i-1]+fib[i-2],注意到这里只与3个数据单元有关,那么只需要在寄存器上保存这三个值就可以了。但递增的i应该使得寄存器中的内容变化,这里如何处理呢?
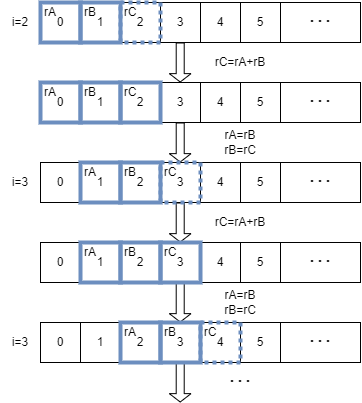
若以rA、rB、rC分别表示存储fib[i-2]到fib[i]的寄存器,观察图中数据的变化可以发现,循环中的每轮结束后,三个寄存器便会沿着fib[]数组向右滑动一格。换句话说,rA中的值会变成rB中的值,rB中的值会变成rC中的值,而rC中的值则等待在下一轮中被求出。
还有一个小技巧,如果严格按照Part 0中的写法,除了为rA、rB赋值外,还要给fib[0]、fib[1]赋对应的相同值,有没有办法减少这些“不好看”的代码呢?逆推出rA=fib[-2]=-1与rB=fib[-1]=1即可。
1 | // FibonacciLoopTripleReg |
1 | # FibonacciLoopTripleReg |
现在,C代码的for循环中只有fib[i]=rc一条访存指令了,汇编代码中,每轮循环确实也只有movq %rsi, (%rax,%rdx,8)一次内存访问向fib[i]写入寄存器rc中的数据。值得注意的是,计算rc=ra+rb被优化为一条指令leaq (%rdi,%rcx), %rsi,最终速度(650ms)比Part 1(1293ms)快了2倍。
2:减少到2个寄存器
尽管已经减少到了只使用3个寄存器,而不读取内存中的数据,还是要思考一下,能否再减少寄存器的使用呢?
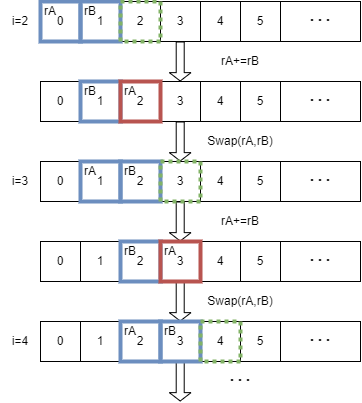
Part 1中使用了三个寄存器rA、rB、rC,注意到rC在for循环的每轮开始时的值总是不被关心的(等待被求出),而rA的值在for循环的每轮rC=rA+rB被求出后总是被丢弃。那么可以将rB的值直接加到rA中得出rC。但此时rA变成了rC,而每轮结束时,本该rA变成rB、rB变成rC,那么只需要交换一次rA与rB即可。
1 | // FibonacciLoopDoubleReg |
1 | # FibonacciLoopDoubleReg |
需要注意的是,C语言中没有swap()函数,而如果使用三次异或指令的话,会被编译优化成与Part 1中一样的代码。实际上哪怕只执行1次,xor所需的时间也比mov要久,更何况是3次xor比2次mov了。这里使用了xchg指令来交换两个寄存器,但最终结果(761ms)也比Part 1(650ms)要慢。
3:循环展开
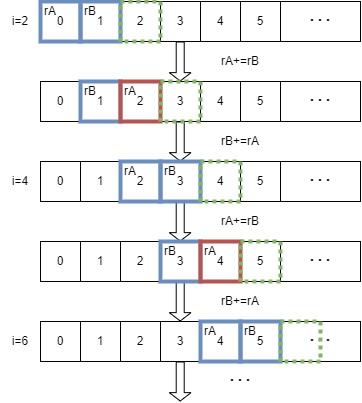
关于何为循环展开,其实在这里没有起到明显的优化作用,就放在以后讨论了。但循环展开却为这里提供了一个思路,直接上图与Part 2对比,一图胜千言,相信一切尽在不言中了。
1 | // FibonacciLoopUnrolling |
1 | # FibonacciLoopUnrolling |
尽管每轮for循环中执行了两次mov指令写入内存,但每轮的迭代变量i+=2,故mov指令写存的执行总数与Part 2中是相等的,但循环中不再需要交换寄存器中的值了,也没有像Part 1中使用mov对寄存器的滑动,故速度最快(498ms),接近Part 0(1293ms)的3倍。
4:循环展开(求斐波那契数)
这里额外设计了一个
1 | // FibonacciNumLoopUnrolling |
1 | # FibonacciNumLoopUnrolling |
由于不需要求数列,也就不需要写内存了,结果(159ms)比需要写内存的版本(498ms)快了3倍。